

























BandiView Pro - 更好用的 Windows 看图工具 (支持 HDR / HEIC / 漫画 / 免解压看图)
新一代看图利器 Windows 2024-05-1


再次大放水 之前「支付宝」为了拉拢用户,曾多次大规模发放大额红包。而今天再一次开启“狂送钱”官方活动!大幅提高了红包金额,基本人均能领 1~20 元, 能直接线下支付时当现金用!没有套路……
Ubuntu 24.04 LTS 中文桌面版/服务器正式版ISO镜像下载 - 超流行易入门的 Linux 系统
重磅 LTS 新版发布 Linux 2024-04-27


GameBoy (GB) 是任天堂公司推出的一款掌上游戏机,于 1989 年在日本首次发售。它是第一款真正流行的便携式游戏机,拥有一块绿色的单色屏幕,可以运行各种不同类型的游戏卡带。GameBoy 在当……
Fedora 40 正式版镜像下载 - 更新快 / 软件包版本新 / 开放的 Linux 发行版系统
v40 正式版发布 Linux 2024-04-26


GBA(GameBoy Advance)是由任天堂公司于 2001 年推出的一款掌上游戏机,可谓是一代神机!它是 GameBoy 系列的第四代产品,是 GameBoy Color 的升级版,后面也发布了改版折叠屏的 GBA-SP,但性能和……
爷青回!苹果 Delta 模拟器 - 免费开源在 iPhone 上玩 GBA / NDS / FC / N64 等游戏
开源免费 / 情怀神器 iOS 2024-04-22


FC (Family Computer) 是任天堂公司于 1983 年 7 月 15 日在日本推出的一款 8 位游戏机,外观以红白相间而得名,有人俗称它为“任天堂红白机”。而在欧美,其名称则叫做 NES (Nintendo Entertainment S……


四月限时优惠最近我们又迎来了「正版软件优惠活动·四月」的活动了!会场精选了一批高效办公软件和系统增强工具,快来看看有没有你需要或期待的那一款吧~前往优惠会场挑选
下单时填入优惠码……

Parallels Desktop 被称为 macOS 上强大的虚拟机软件。可以在 Mac 下同时模拟运行 Win、Linux、Android 等多种操作系统及软件而不必重启电脑,并能在不同系统间随意切换。
最新版 Parallels Desktop 19 (PD19) 完全支持 macOS Sonoma、Ventura 和 Windows 11 / Win10 及 CentOS、Ubuntu 等,并充分优化!可不重启直接在 Mac 系统上运行 Linux 和 Win 应用程序和游戏、使用如 Office、VisualStudio、AutoCAD、Matlab 等工具。新版 PD19 还支持 OpenGL 4.1 与 DirectX 11,大幅提升速度及 3D 游戏图形性能!!妥妥的是 Mac 必备神器……
. . . . .
写论文神器论文写作是一项既重要又具挑战性的任务。对于忙碌的大学生、研究生以及各学科领域的研究人员来说,面对繁杂的研究主题和严格的格式要求时,常常感到不知所措。此时,「笔灵 AI 论……
优麒麟 Ubuntu Kylin 中国版 24.04 LTS 操作系统中文版ISO镜像下载 (官方定制版)
重磅升级 24.04 LTS Linux 2024-04-17


个人免费/邀测薅羊毛随着 AI 技术的发展,除了 ChatGPT、Claude、Gemini、Coze 等聊天式的智能对话机器人之外,对于开发者、学习编程的朋友还有更加高效强大的工具——AI 编程助手 (代码补全工具)。除了热门的……

被誉为 “世界流行的便宜特小型电脑” 的「树莓派」Raspberry Pi 是一款性价比超高的迷你电脑主机 (仅有信用卡大小),深受全球开发者、极客、技术爱好者们的追捧和喜爱。
树莓派可以安装多种 Linux 系统发行版 (官方为 Debian 衍生版 / 也可完美支持 Ubuntu),可当服务器搭建各种网站、应用服务来使用,也能用来学习编程、控制硬件或日常办公。由于树莓派的体积很小很轻,并且功能极其丰富强大,这也使得它的应用范围和潜力几乎是无限的……
. . . . .
重磅好消息刚刚 OpenAI 宣布,ChatGPT 现在起「不需要注册」就能免登录直接使用了!现在全球 185 个国家和地区有超过 10 亿人在借助 AI 进行学习和工作,而 OpenAI 正在慢慢开放这项服务。免除繁琐的注……
DAMA 自动打码 APP 太爱了!智能识别出图片中隐私文字信息打码涂抹/加水印
iOS 2024-04-12

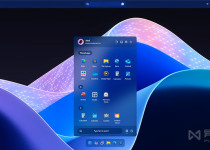
我们都期待微软 Windows 12 将会在不久后推出,据说 Win12 新版本将特别注重整合 AI 人工智能的各种先进技术,旨在全方位提高各行各业的工作效率。但目前为止,除了微软自己,我们都还……



